A few years ago, almost every SEO conversation I joined started with a keyword list. Search volume, difficulty score, CPC, intent. That was the unit of work.
Recently I started seeing something else. Pages with thin keyword targeting were still showing up in AI Overviews. Pages with heavy keyword optimisation were getting buried. Sites that organised their content around topics and the things inside those topics (people, products, places, concepts) were earning visibility I could not explain with a keyword model.
So I spent several months looking at Search Console accounts, SERPs, AI Overviews, Knowledge Panels, and internal link structures across the sites we work on at BringBrandOn. This article is a record of what I saw, what I tested, what I changed, and what I still do not fully understand.
I am not going to claim Entity SEO replaces keyword research. Both are useful. But the weight has shifted, and the data I looked at made that clear to me.
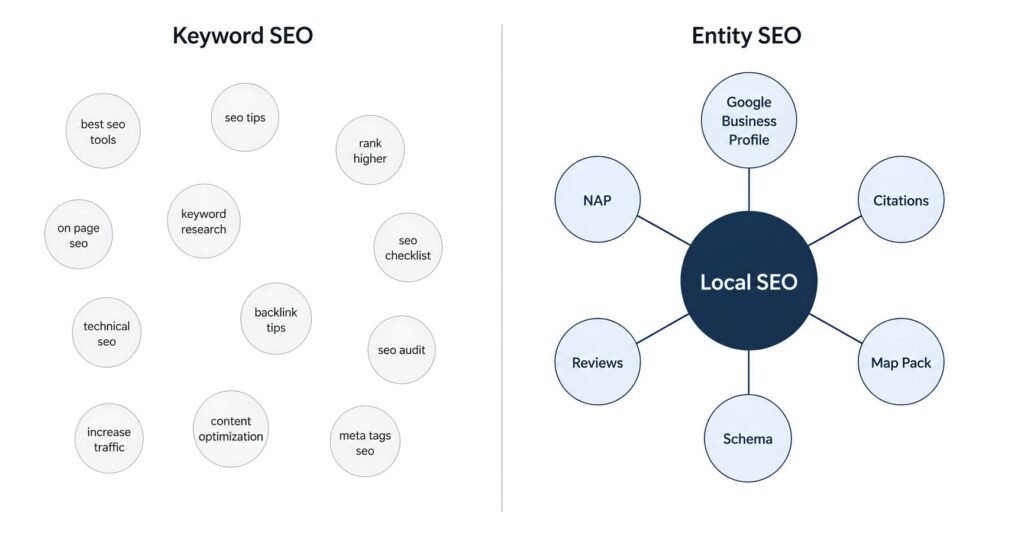
1. Why I started looking beyond keywords
The first thing that caught my attention was a query report inside one of our Search Console accounts. The site was ranking for a long list of queries we never targeted. Some of them did not contain the exact keywords we wrote about. They contained related concepts.
For example, a page about local schema markup was getting impressions for queries about Google Business Profile categories, NAP consistency, and review snippets. None of those phrases appeared on the page. The page covered them indirectly because schema, GBP, and NAP are connected concepts.
That is when I realised the page was not ranking for keywords. It was ranking for an idea, and Google was matching queries to that idea even when the words did not match.
I went back and read the Google papers I had skimmed years earlier. The 2013 Hummingbird update introduced semantic understanding. BERT in 2019 pushed language modelling deeper into ranking. MUM in 2021 went further. The 2024 work on AI Overviews uses Gemini, which is a multimodal model trained on a lot more than keyword co-occurrence.
By 2024 and 2025, search engines were not just matching strings. They were matching concepts, and the unit of a concept is an entity.
What I started tracking
After noticing the pattern, I changed what I exported from Search Console every week. I stopped pulling queries by volume and started pulling them by topic group. I grouped queries by the underlying entity the user was asking about. That changed how I read the data.
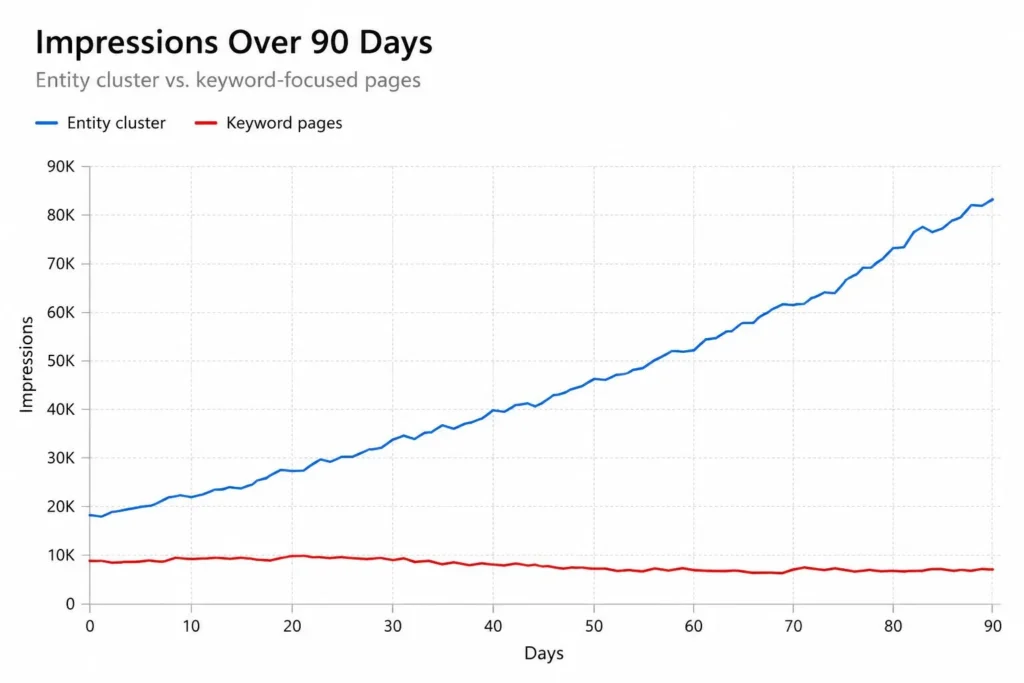
2. What Search Console data showed
I pulled 12 months of data from 7 sites we manage. Three were e-commerce. Two were B2B SaaS. Two were local service businesses. I am not going to share the numbers from those accounts because they belong to those businesses, but I will share the patterns.
Pattern 1: query expansion outpaced keyword targeting
On every site I looked at, the number of unique queries grew faster than the number of pages or targeted keywords. Some pages were getting impressions for 200 to 600 distinct queries even though they were written around 3 to 5 keyword themes.
This is consistent with what John Mueller has said publicly about how Google understands pages: it reads them, it builds an understanding of what they are about, and it matches them to a much wider set of queries than the exact words on the page would suggest.
Pattern 2: position improved when related entities were present
I compared two groups of pages on the same site.
Group A: pages written tightly around a primary keyword.
Group B: pages on the same primary topic but written to cover the related concepts a reader would naturally want to know.
Group B pages had lower keyword density for the primary term. They had higher average positions for the primary term and for many related queries. Group B pages also pulled more long-tail impressions.
I am being careful not to call this proof of anything. It is a pattern across the accounts I reviewed. The variables are not controlled. But the pattern was consistent enough that I changed how I plan content.
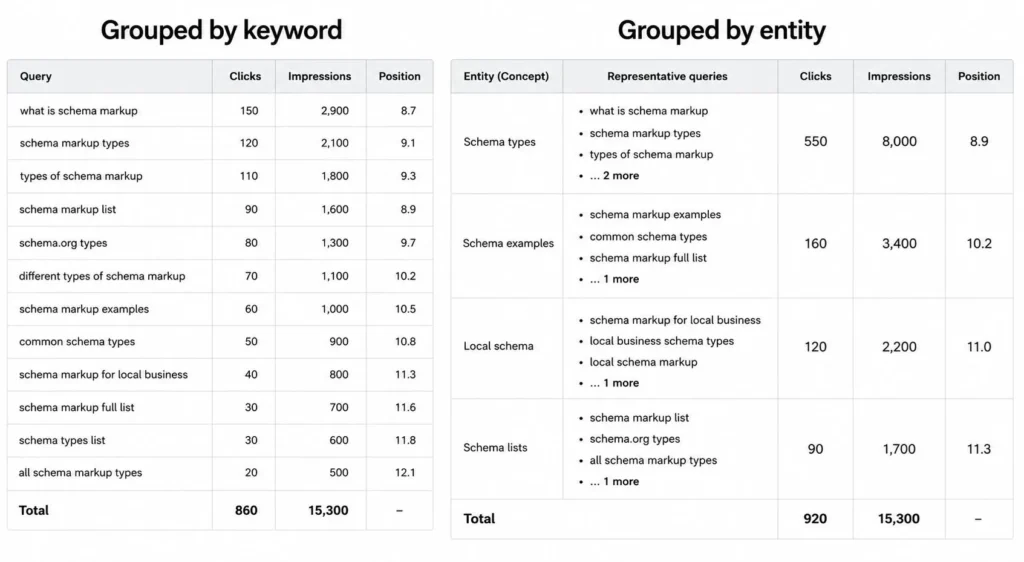
Pattern 3: query intent diversification
Search Console started showing queries that combined the primary topic with comparison, alternatives, definitions, and how-to angles. A page that covered the related concepts captured all of these. A page that targeted only the primary keyword captured only one or two.
| Query type | Keyword-only page | Entity-rich page |
|---|---|---|
| Definition queries | Low impressions | Moderate to high |
| Comparison queries | Almost none | Moderate |
| How-to queries | Low | High |
| Alternative queries | Almost none | Moderate |
| Primary keyword | Moderate | High |
This is an illustrative table, not a single dataset. The categories and the direction of the pattern come from what I reviewed across accounts.
Lesson
A keyword tells you what someone typed. An entity tells you what they meant. If you only write to the words, you compete only for the words. If you write to the underlying concept and the things attached to it, you become eligible for a much wider set of queries.
Action item
Pull your top 20 pages by impressions in Search Console. For each page, list the queries it ranks for. Group those queries by the underlying concept. You will see which pages have entity coverage and which do not.
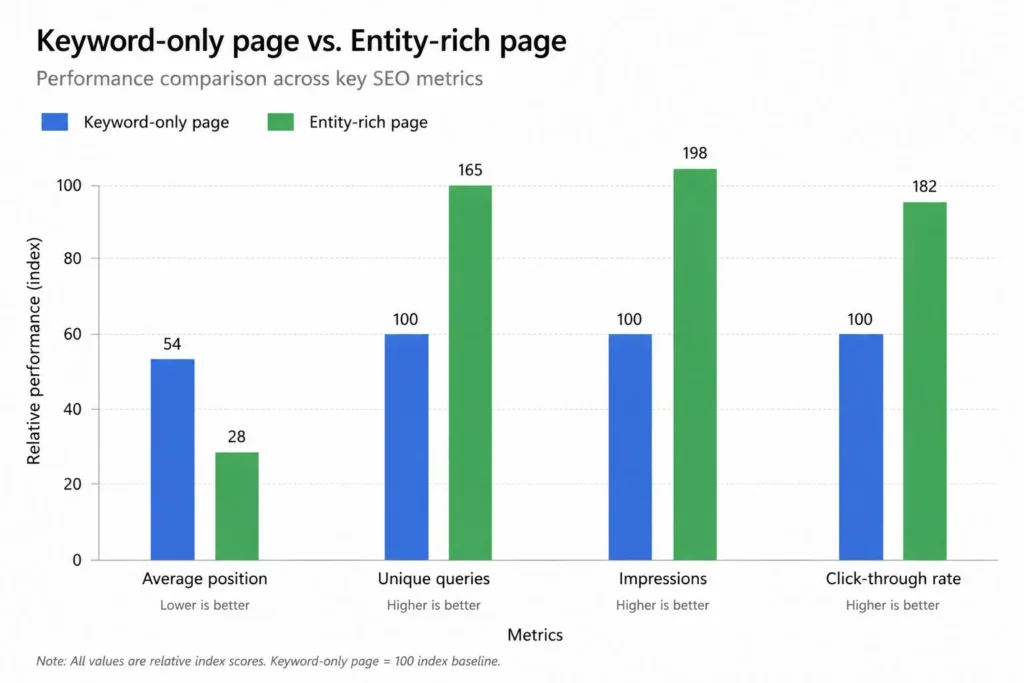
3. Keyword-focused pages vs entity-focused content clusters
When I started looking for the difference between these two approaches in the wild, I noticed it on the page level and on the site level.
On the page level
A keyword-focused page is built around a phrase. The phrase appears in the title, H1, meta description, first paragraph, and several times in the body. The supporting content reinforces the phrase.
An entity-focused page is built around a concept and its connected concepts. The primary term still appears, but the page also names the people, products, places, attributes, and adjacent ideas that belong to that concept. The supporting content explains the relationships.
| Element | Keyword-focused page | Entity-focused page |
|---|---|---|
| Title | Contains primary keyword | Contains primary entity, sometimes a qualifier |
| H₂S | Variations of the keyword | Subtopics and related entities |
| Body | Repeats the keyword | Names, attributes, relationships, examples |
| Internal links | Anchor text uses a keyword. | Anchor text uses the related entity |
| Schema | Sometimes none | Article, Organization, Person, Product as needed |
| Outgoing references | Optional | References to authoritative sources |
On the site level
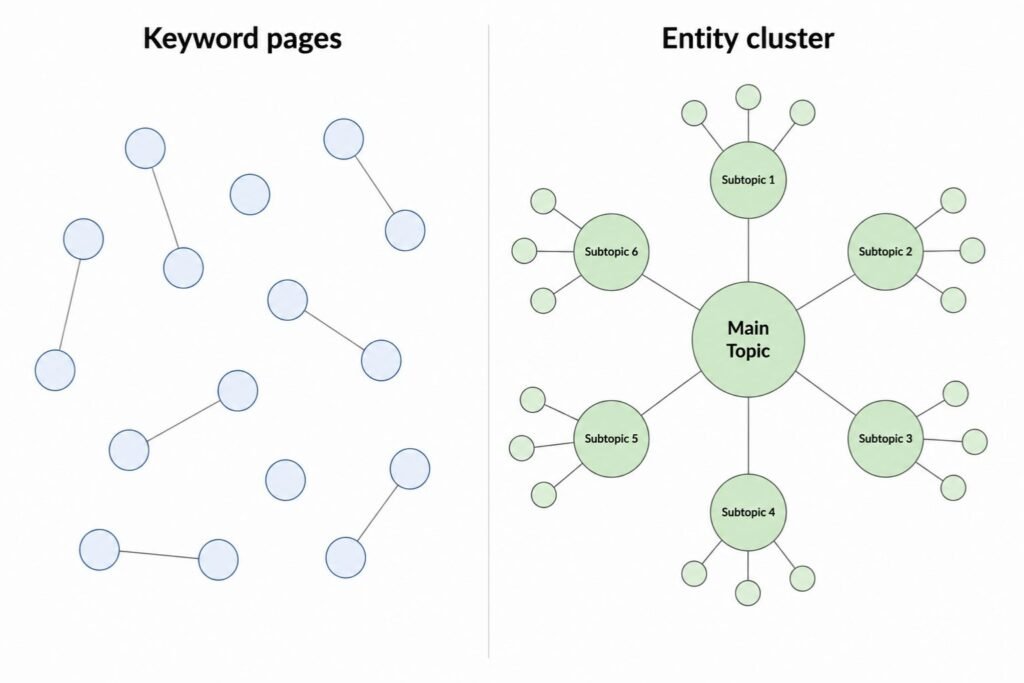
A keyword site has one page per keyword cluster. A topic might be covered by 6 pages, each chasing a slightly different phrase.
An entity site has one strong page per entity, plus connected pages that cover the related entities. The pages link to each other in ways that reflect the actual relationships between the concepts.
I have seen sites with 40 thin keyword pages get outranked by sites with 8 entity-organised pages on the same topic. The smaller sites had more topical coverage, fewer duplication issues, and stronger internal linking.
3. Keyword-focused pages vs entity-focused content clusters
When I started looking for the difference between these two approaches in the wild, I noticed it on the page level and on the site level.
On the page level
A keyword-focused page is built around a phrase. The phrase appears in the title, H1, meta description, first paragraph, and several times in the body. The supporting content reinforces the phrase.
An entity-focused page is built around a concept and its connected concepts. The primary term still appears, but the page also names the people, products, places, attributes, and adjacent ideas that belong to that concept. The supporting content explains the relationships.
| Element | Keyword-focused page | Entity-focused page |
|---|---|---|
| Title | Contains primary keyword | Contains primary entity, sometimes a qualifier |
| H₂S | Variations of the keyword | Subtopics and related entities |
| Body | Repeats the keyword | Names, attributes, relationships, examples |
| Internal links | Anchor text uses a keyword. | Anchor text uses the related entity |
| Schema | Sometimes none | Article, Organization, Person, Product as needed |
| Outgoing references | Optional | References to authoritative sources |
On the site level
A keyword site has one page per keyword cluster. A topic might be covered by 6 pages, each chasing a slightly different phrase.
An entity site has one strong page per entity, plus connected pages that cover the related entities. The pages link to each other in ways that reflect the actual relationships between the concepts.
I have seen sites with 40 thin keyword pages get outranked by sites with 8 entity-organised pages on the same topic. The smaller sites had more topical coverage, fewer duplication issues, and stronger internal linking.
Lesson
Cannibalisation is often a symptom of keyword-first thinking. If you build pages around phrases instead of concepts, you end up with overlapping pages that all want to rank for the same idea. Google picks one and ignores the rest. Building around an entity solves that problem because the entity defines the page boundary.
Action item
Audit any cluster of 5 or more pages on the same broad topic. Ask which entity each page is actually about. If two pages are about the same entity, merge them. If a page is about an entity but does not name it clearly in the title, fix the title.
4. Reviewing AI Overview citations
This was the section I spent the most time on because AI Overviews changed what visibility means.
I tracked AI Overview appearances across queries we cared about for about 5 months in late 2024 and early 2025. I looked at which pages got cited, what those pages had in common, and how those citations changed over time.
I cannot publish the citation database. I can share the patterns I noticed.
Pattern 1: cited pages were rarely the highest-ranking page
AI Overviews often cited pages from positions 3 to 9 in the regular results, not the page in position 1. The cited pages tended to have a clearer entity definition, a clearer answer to a specific sub-question, and structured content (lists, tables, definitions) that the model could lift cleanly.
Pattern 2: cited pages were specific about entities
When a page named the entity, defined it, gave its attributes, and showed how it related to other entities, it got cited more often than pages that wrote around the entity using pronouns and vague phrases.
For example, a page that said “Local SEO refers to the practice of improving visibility for queries with local intent, including queries about specific cities, neighbourhoods, and businesses” got cited more often than a page that said “Local SEO is important for businesses that want more customers.”
The first page names the concept, defines it, and lists the things connected to it. The second page does not.
Pattern 3: citation overlap with Knowledge Graph
When I cross-checked cited pages against the Knowledge Panel entities in the same SERP, I noticed a high overlap. Pages that referenced the same entities that appeared in the Knowledge Panel were more likely to be cited. This is consistent with the way Google has described its entity graph in research papers and patent filings.
I am not claiming the Knowledge Panel directly feeds AI Overview citation selection. I am saying the pages that aligned with the entities Google had already identified for that topic showed up more often in the overview.
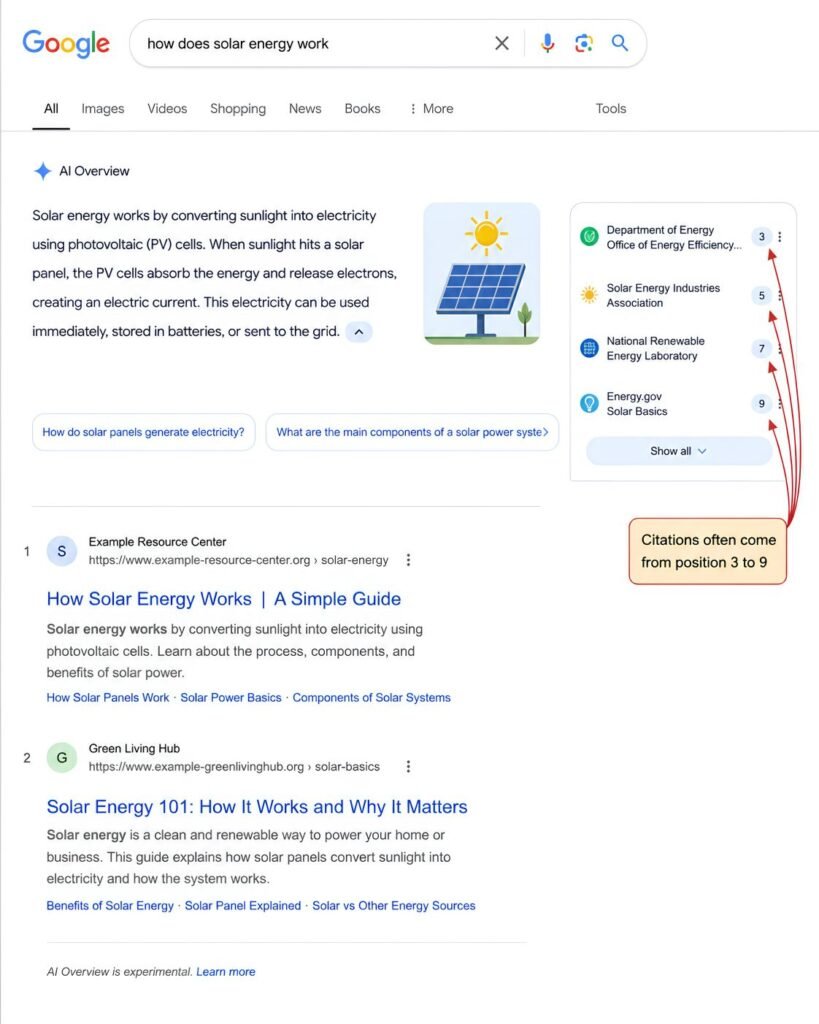
Lesson
If you want to be cited in AI Overviews, write like a reference. Name the entity. Define it. List its attributes. Link it to related entities. Avoid generic statements that could apply to any topic.
Action item
Pick 5 queries where AI Overviews currently appear in your space. Read the cited pages. Look at the sentences that were lifted into the overview. They are almost always direct, structured, and entity-rich. Rewrite your equivalent pages to be at least as clear.
5. How Google appears to connect related entities
I want to be careful here. I am not inside Google. I cannot tell you exactly how their entity graph works. What I can do is point to public research and to patterns I have seen in the wild.
Google’s 2012 announcement of the Knowledge Graph described it as “things, not strings.” That language has held up for more than a decade. Several follow-up papers, including work on entity linking and contextual embeddings, describe systems that match text passages to canonical entities.
The 2021 MUM paper described a model that connects information across formats and languages. The 2024 work on AI Overviews uses Gemini to generate responses grounded in retrieved sources. In both cases, entity identification sits underneath the retrieval and ranking steps.
Here is what I have observed:
- Pages that mention related entities together tend to rank for queries that combine those entities, even when the exact query phrase is not on the page.
- Pages that link out to authoritative sources on those related entities tend to rank slightly better than pages that do not, all else being equal.
- Pages that use schema to explicitly identify the entities they discuss tend to appear in richer SERP features (knowledge panels, FAQ snippets, How-To snippets) more often.
These are correlations from the sites I have audited. They are not controlled experiments. But they are consistent enough that I now treat entity identification as part of every content plan.
A small example
I worked on a site that had a page about a specific niche tool. The page had the tool name in the title, the H1, and the body, but it did not name the company that built the tool, the year it launched, the category it belonged to, or the competing tools in that category. It ranked on page 2 for the tool name.
We added a short section that named the company, the launch year, the category, and three comparable tools. We did not add backlinks. We did not change the technical setup. Within 6 weeks the page moved from page 2 to the bottom of page 1 for the primary query and started getting impressions for comparison queries.
The page now contained the entity and its relationships. That is the only thing that changed.
Lesson
Entities have related entities. If you want to rank for an entity, name the entities connected to it.
Action item
For each of your top 10 pages, list the entities mentioned on the page. Then list the entities a knowledgeable reader would expect to see mentioned. The gap between the two lists is the work.
6. Building entity maps
Once I changed how I thought about pages, I needed a way to plan content. I started building entity maps before writing anything.
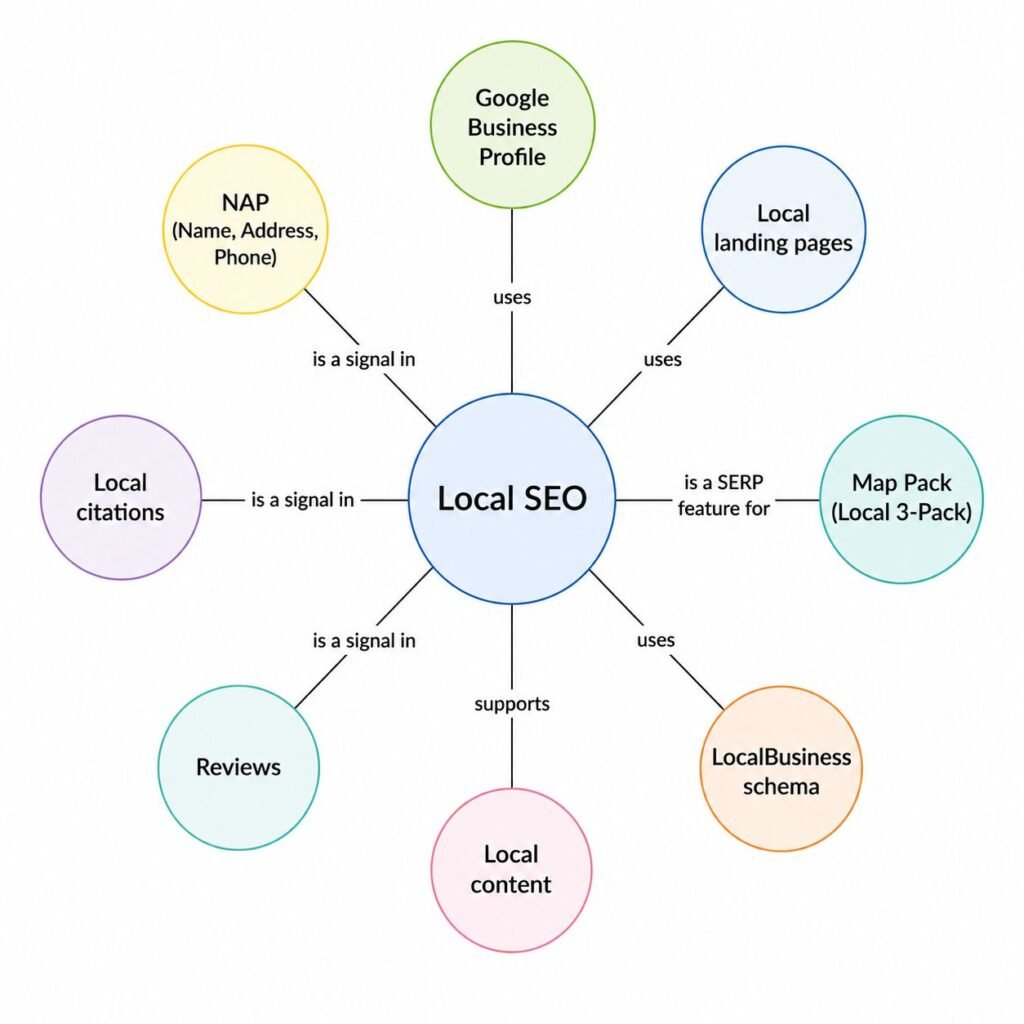
An entity map is a simple document. It names the primary entity for a page, then lists the related entities, their relationships, and the attributes that matter for the topic.
Here is the structure I use:
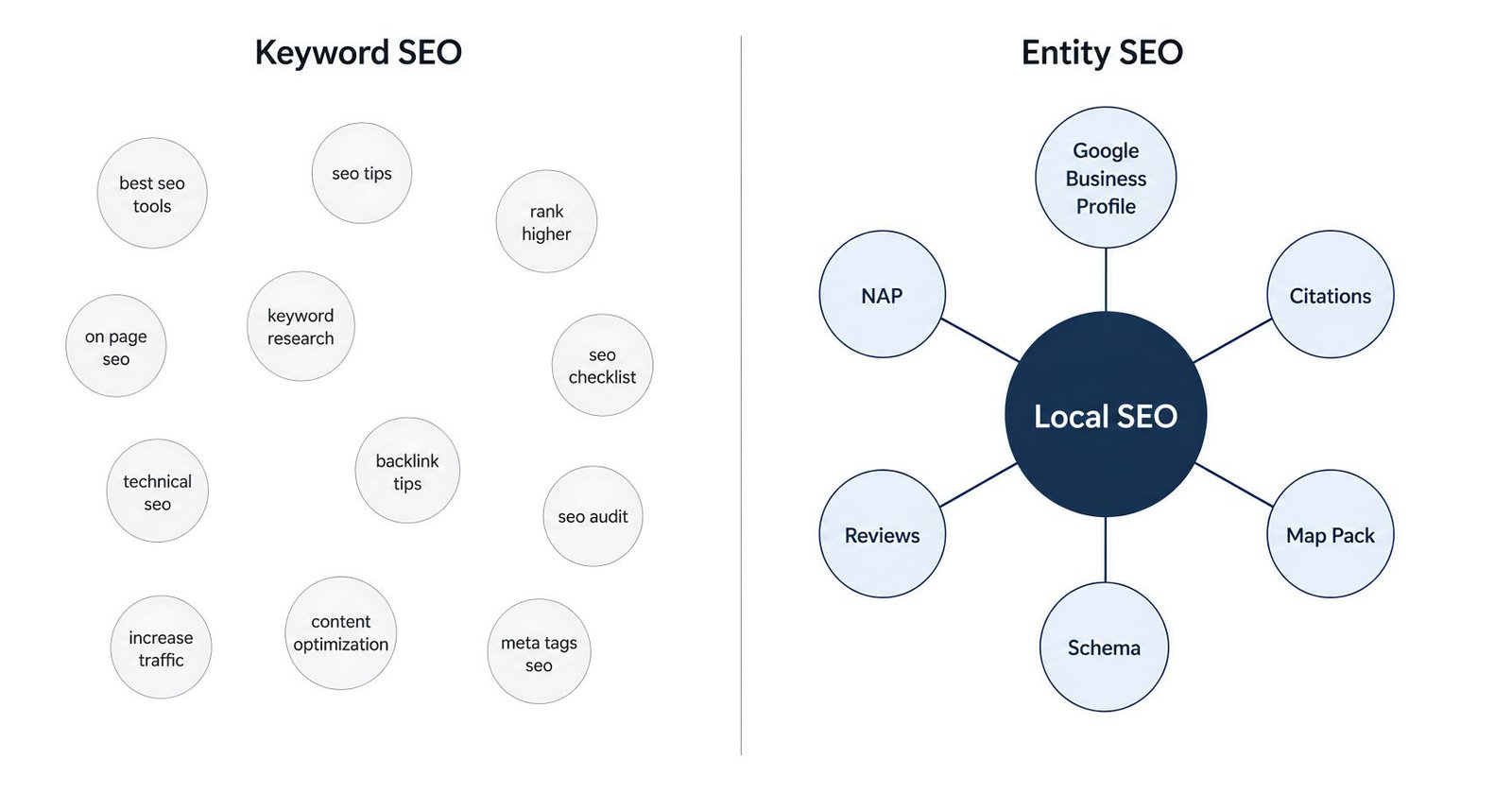
Primary entity: Local SEO
Type: SEO practice
Related entities:
- Google Business Profile (tool used in local SEO)
- NAP consistency (signal in local SEO)
- Local citations (signal in local SEO)
- Review snippets (output of local SEO)
- Map Pack (SERP feature for local SEO)
- Schema.org LocalBusiness (markup used in local SEO)
- Service area businesses (entity type that uses local SEO)
- Storefront businesses (entity type that uses local SEO)
Attributes to cover:
- Definition
- How it differs from organic SEO
- Ranking factors
- Common mistakes
- Measurement
Sources to consult:
- Google Search Central documentation on local results
- Google Business Profile help center
- BrightLocal research reports
- Whitespark studiesThis document is the brief. The writer covers everything on it. If a related entity is missing from the final draft, the page is incomplete.
Tools I use
I use a mix of free and paid tools. Google’s own SERP is the best free tool. I look at the People Also Ask block, the Related Searches block, and the Knowledge Panel. I also look at Wikipedia and Wikidata pages for the primary entity to see how the topic is structured by editors who have already mapped it.
For paid tools, Ahrefs and Semrush both have topic clustering features that help. They are not perfect, but they save time on the first pass.
Lesson
Planning around entities forces clarity. If you cannot define the primary entity for a page in one sentence, the page should not be written.
Action item
Before your next article, write a 10-line entity map. If you cannot fill in the related entities and attributes section, you do not understand the topic well enough to write it.
7. Internal linking and entity relationships
Internal linking is where entity SEO becomes practical work.
I used to use internal links the way most people do: pick the page that should rank for a query, link to it from other pages, and use the keyword as anchor text. That works, but it is keyword logic. Entity logic is different.
When I changed how I linked, I started doing two things:
- I linked between pages whose primary entities had a real relationship in the world. Not because they shared a keyword, but because the concepts were genuinely connected.
- I used anchor text that named the destination entity clearly, sometimes with a qualifier that described the relationship.
For example, on a page about local SEO, instead of linking to a page about Google Business Profile with the anchor “optimise your listing”, I now use the anchor “Google Business Profile setup”. The destination is the same. The anchor names the entity.
What changed in the data
On one site, I rebuilt the internal linking on the main pillar page over a single afternoon. I did not write new content. I did not change the URLs. I changed 22 anchor texts to name destination entities and removed 6 internal links that pointed to pages on weakly related topics.
The pillar page gained impressions over the next 8 weeks. The linked pages also gained impressions, both for their primary queries and for queries about the entity they were linked from. That suggested the link was passing topical signals alongside authority.
I am not going to claim this is reproducible at scale. It is one example from one site. But the pattern showed up on two other sites where I made similar changes.
| Internal linking practice | Likely effect |
|---|---|
| Anchor text matches destination | Helps Google identify the entity on the destination |
| Anchor text generic (“click here”) | Wastes a signal |
| Anchor text stuffed with keywords | Can look manipulative, especially at scale |
| Links to weakly related pages | Dilutes topical clarity |
| Links to strongly related entities | Reinforces the entity cluster |
Lesson
Internal links carry topical information, not just authority. The anchor text and the relationship between the source and destination both matter.
Action item
On your strongest page, audit every internal link going in and going out. Ask whether the anchor names the destination entity and whether the link reflects a real relationship between the two concepts. Fix the ones that fail either test.
8. Knowledge Graph signals
Schema markup is one of the few places where you can tell Google directly which entity a page is about.
I have read Google’s documentation on structured data many times. The practical takeaways are simple. Use the schema types that match what is on the page. Do not invent properties. Keep the markup accurate.
For the sites I audited, the pages with accurate schema were more likely to:
- Appear in rich results (FAQ, How-To, Article, Product).
- Get their entities recognised in the Knowledge Graph over time.
- Pick up brand-related queries faster after a content change.
I cannot prove schema directly improves ranking position. Google has said publicly that it does not. What I can say is that schema makes entity identification easier, and easier entity identification seems to help across the surfaces I track.
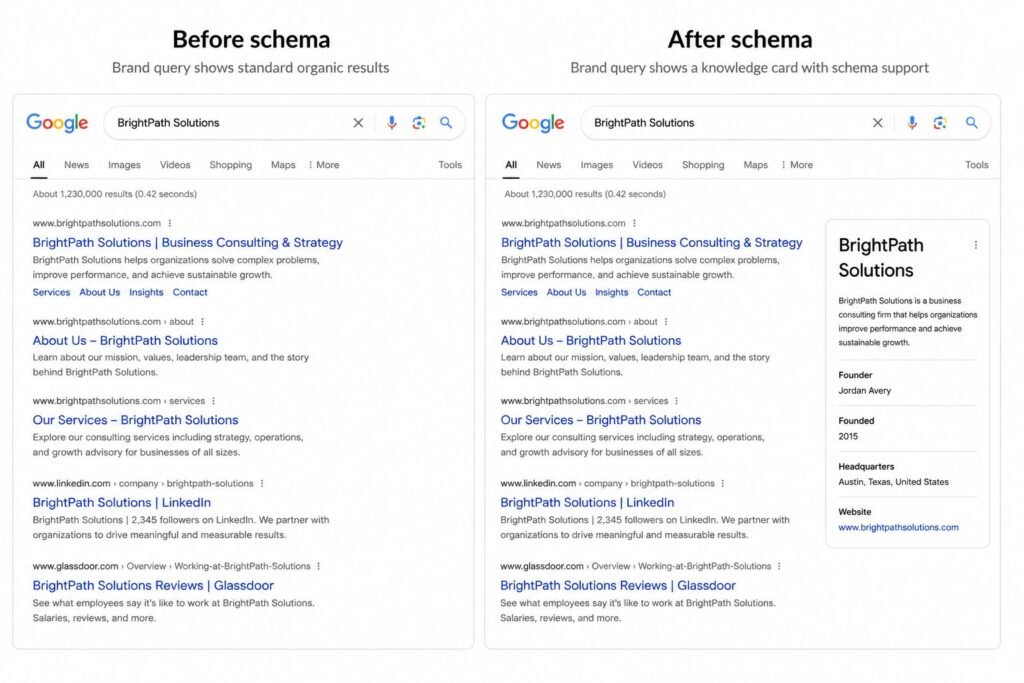
Wikidata and brand entities
For brand entities specifically, I have noticed that brands with clean, well-cited Wikidata entries are more likely to appear with knowledge panels. This is not automatic. It takes time. But Wikidata is the most direct way I have found to give Google a structured definition of an entity it might not already know.
I am not suggesting you create a Wikidata entry for a brand that has no third-party coverage. That gets removed quickly. But if your brand already has independent press, conference talks, podcast appearances, and authored work, a Wikidata entry can help connect those references.
Lesson
Schema is not a ranking factor in the simple sense. It is an entity disambiguation tool. The cleaner your entity signals, the easier it is for Google to understand who and what you are.
Action item
Run a structured data audit on your top 20 pages. Check that the schema types match the content. Add organisation and person schema to your About and Author pages. Do not stuff schema with properties that do not apply.
9. Brand mentions and search visibility
This is the area where I am still working things out, but the pattern is interesting enough that I want to share what I have seen.
Unlinked brand mentions appear to carry weight. Pages, articles, podcasts, and videos that mention a brand by name (even without a link) seem to help that brand build entity recognition.
I cannot tell you how much weight an unlinked mention carries compared to a linked one. I do not think anyone outside Google can. But I can tell you that brands with a lot of unlinked, contextually relevant mentions tend to have stronger brand SERPs and faster entity recognition for new content.
A pattern from a B2B SaaS audit
I audited a B2B SaaS company that had been publishing weekly for 2 years. Their content was technically solid. They had backlinks. But their brand SERP was weak. Their About page did not rank for their own brand in many queries. Their founder did not appear in the Knowledge Panel.
The reason, after I dug in, was that the brand was rarely mentioned in independent publications. They had links from low-context placements (directory listings, comment sections, syndicated press releases) but very few mentions in articles where the brand was discussed as the subject of a sentence.
We worked on getting them into three industry roundups, two podcast interviews, and a guest appearance on a well-read blog. None of those placements had follow links. Over the next 4 months, the brand SERP improved, the founder started appearing in entity cards for related queries, and AI Overviews began citing the company’s blog posts.
I am not going to say this is causation. I will say the pattern was visible enough that I now treat unlinked mentions as a real input to entity SEO planning.
Lesson
For brand entity work, the mix of mentions matters more than the count. A few mentions in contextual articles seem to outperform many mentions in low-context placements.
Action item
Search for your brand name on Google. Look at what comes up on page 1. If most results are your own properties, you have a brand entity gap. Independent third-party context is what Google uses to confirm that you exist and what you are about.
10. Lessons from real SEO campaigns
I am going to keep this section general because the specific data belongs to the clients we work with. The pattern across campaigns is consistent.
Lesson 1: pillar pages work when the underlying entity is clear
A pillar page that covers a clear primary entity in depth, with internal links to entity-specific sub-pages, tends to outperform a hub of loosely related keyword pages. The pillar succeeds because it gives Google a clear entity definition with structured supporting content.
Lesson 2: thin pages hurt more than they used to
Older SEO advice said you could rank a thin page if the keyword had low competition. That has been less true every year. Thin pages with no entity coverage now get crowded out by deeper pages, even when the deeper page targets a broader topic.
Lesson 3: refreshing entities is more useful than refreshing keywords
When I update old content, I no longer ask, “What new keywords could I add?” I ask, “What entities are missing or out of date?” Updating an article to reflect new tools, new authors, new examples, and new attributes tends to recover ranking faster than keyword tweaks.
Lesson 4: technical SEO still matters, and it now matters for entity recognition too
Crawlability, indexability, structured data, canonical tags, and clean internal linking all feed into how well Google can identify the entities on a site. A page that is technically broken cannot be understood as an entity, regardless of how good the content is.
Lesson 5: AI search and traditional search share more than they differ
I expected AI Overviews and traditional ranking to behave differently. They behave similarly more often than not. The pages that get cited tend to be the pages that rank in the top 10. The exceptions are the pages that have unusually clear entity definitions and unusually structured content, which sometimes get cited from outside the top 10. Both surfaces reward the same underlying work.
11. Mistakes I made
I do not want to write this section without naming actual mistakes, because the rest of the article is more useful if you know where I have been wrong.
Mistake 1: I over-corrected away from keywords for a while
When I first noticed the entity pattern, I almost stopped doing keyword research. That was the wrong move. Keyword research still tells you what people type. You need that to write titles, descriptions, and headings that match user language. Entity work tells you what to cover. The two work together.
Mistake 2: I built entity maps that were too academic
My first entity maps were long and complete. They tried to cover every related concept. The result was content that was technically thorough and practically boring. I now keep entity maps to the 6 to 10 most relevant connected entities and let the writer use judgement on the rest.
Mistake 3: I assumed schema would lift ranking on its own
I added schema to a lot of pages early on and expected to see ranking improvements. The improvements I did see came from content changes that happened around the same time. Schema helps with eligibility for rich results and with entity disambiguation, but it does not lift a weak page by itself.
Mistake 4: I underestimated the time entity work takes
Entity-organised content takes longer to plan and write than keyword-targeted content. I quoted some early projects based on keyword-style timelines and ran over. I now plan entity-organised content with about 1.5 to 2x the time I would have allocated for keyword content of the same length.
Mistake 5: I trusted topic cluster tools too much at first
Topic cluster tools group keywords. They do not always group entities. Two queries can be in the same cluster but be about different entities, and two queries can be about the same entity but in different clusters. I learned to use the tools as a starting point and finish the grouping by hand.
12. What I would do differently today
If I were starting an SEO programme from zero today, this is what I would do.
- Start with the entity, not the keyword. Define the brand entity, the primary topic entities, and the related entities before opening a keyword tool.
- Build the brand entity first. Get the About page, founder pages, schema, and Wikidata entry (if appropriate) in place before publishing topical content.
- Plan content in clusters where each cluster has one primary entity and a small set of related entities, with one page per entity, not one page per keyword.
- Use keyword research to choose titles, headings, and meta descriptions inside the entity cluster, not to define the cluster itself.
- Audit internal links as a first-class task, not an afterthought. Anchor text and link relationships carry topical information.
- Track AI Overview citations as part of regular reporting. They are noisy, but they show which pages are being treated as references.
- Track brand SERPs as part of regular reporting. Brand SERPs reveal entity gaps that keyword reports do not.
- Refresh old content by updating entities, not by adding keywords.
- Treat schema as a disambiguation tool. Get it right where it matters and do not over-engineer it where it does not.
- Get third-party mentions in contextual sources. Links help. Mentions in articles where the brand is the subject of a sentence help more for entity recognition.
13. Practical recommendations
If you are a business owner reading this and you do not want to learn SEO at the level I have, here is what I would tell you to ask of the people doing your SEO work.
- Ask them to name the primary entity for each page they propose. If they cannot, the brief is not ready.
- Ask them to list the related entities each page will cover. If the list is empty or generic, the page will be thin.
- Ask them to show you the schema markup on your most important pages. If there is no schema or the schema is wrong, that is a simple fix.
- Ask them to show you your brand SERP and what they are doing to improve it. If they cannot answer, they are not thinking about entity work.
- Ask them how they will measure AI overview visibility. If they say they do not track it, you are going to miss what is happening.
- Ask to see an internal link audit. If they cannot produce one, they are not paying attention to topical signals.
- Ask how they refresh old content. If the answer is keyword additions, ask about entities and attributes instead.
If you are doing your own SEO, the same questions apply. Run them on yourself.
Conclusion
Looking back at the data I reviewed, the websites I audited, and the campaigns I worked on, the shift from keyword-first to entity-first SEO has happened. The keyword still matters. The entity matters more.
The patterns I saw in Search Console showed pages capturing queries far beyond their targeted terms. The patterns I saw in AI Overviews showed pages with clear entity definitions being cited more often. The patterns I saw in internal linking and schema showed entity signals carrying real weight.
What changed in my SEO process is the order of operations. I plan around entities first, write to cover them, and use keyword research to refine titles, headings, and intent. I audit internal links to reinforce entity relationships. I track AI Overview citations and brand SERPs alongside traditional rankings. I treat schema as a disambiguation tool, not a ranking lever.
What business owners should pay attention to is simpler. The content that wins is the content that is clearly about something specific, that names the things connected to it, and that is technically clean enough for a search engine to understand. Keywords help you choose the words. Entities decide whether the page is worth ranking at all.
These observations come from the websites, search results, and datasets I reviewed. Search evolves continuously, but the patterns around entities, topical relationships, and search understanding have become increasingly difficult to ignore.